说明
最近准备在投简历,也是总结总结一下C语言的基础知识,做一些准备。首先说明,下文后面所做的所有的实验都是在win10_1909_x64环境下,gcc version 8.1.0 (x86_64-posix-seh-rev0, Built by MinGW-W64 project),软件使用的是VSCode。在C语言多线程的使用中,在VSCode配置好了C语言的基本环境之后就能直接使用了。
C语言的字与字节
变量大家肯定都熟悉,我的理解是一块内存存储的可变内容。一般来说,多个数据在内存中是连续存储的,彼此之间没有明显的界限,如果不明确指明数据的长度,计算机就不知道何时存取结束。下面对基础的内容进行说明。
首先是位(Bit):表示二进制数码,只有0和1,是计算机处理和保存信息的最基本的单位。
其次是字节(Byte):一个字节由8个位组成,他是作为一个完整单位的8个二进制数码,最开始学习的C语言内容之一就是ASCII编码/《美国国家信息交换标准代码》,下面的图展示了AscII编码的一些信息,里面我觉得印象深刻的圈出来了。
最后是字(Word):一个字由两个字节组成,它表示计算机处理指令或者数据的二进制位数。通常称16位是一个字,32位是一个双字,64位是两个双字。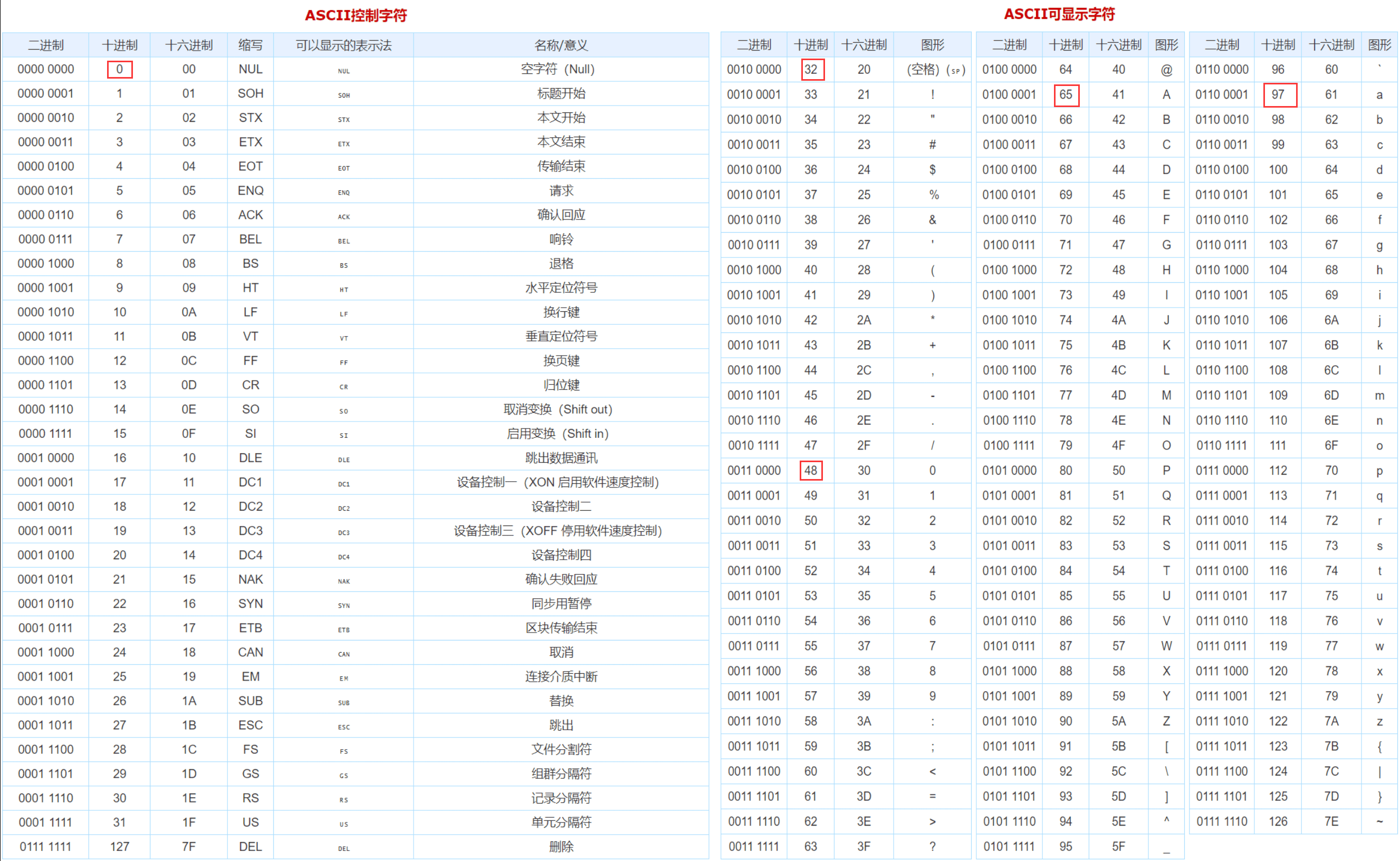
C语言的变量长度
变量的长度,准确来说应该是便来那个类型所占的字节数,也做一个小小的总结吧,具体内容如下所示:
| 类型 | 长度 |
|---|---|
| char | 1 |
| char[1] | 1 |
| char[2] | 2 |
| short | 2 |
| short[1] | 2 |
| short[2] | 4 |
| int | 4 |
| int[1] | 4 |
| int[2] | 8 |
| float | 4 |
| float[1] | 4 |
| float[2] | 8 |
| double | 8 |
| double[1] | 8 |
| double[2] | 16 |
尤其注意的是C语言中的bool变量,在C98是标准中是没有定义bool类型变量的,直接引用会报错,一般可以用define或者枚举型便来那个来表示,还有一种方法是在头文件中添加”stdbool.h”这个头文件来引用即可,下面是具体的一些代码:
1 | #include "stdio.h" |
数据结构的字节对齐
这个是一个非常重要的知识点,面试经常考,具体是个什么意思呢,跑一下下面的代码就知道了。
1 | #include "stdio.h" |
上面的输出分别是 “12 8 16”,两个基本相同的两个结构体长度是不一样,这个就是字节对齐。现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
对齐的作用和原因:各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些架构的CPU在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐.其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。显然在读取效率上下降很多。
揭示了原因,现在上面的例子应该就比较好分析了,windows 64 位默认 结构体对齐系数为8,32位 结构体对齐系数为4,而且在VC/C++和GNU GCC中都是默认是4字节对齐。
T1结构体分三段:
| 类型 | 长度 |
|---|---|
| 1+1+1 | 4 [对齐4] |
| 4 | 4 |
| 1 | 4 [对齐4] |
T2结构体分两段:
| 类型 | 长度 |
|---|---|
| 1+1+1+1 | 4 |
| 4 | 4 |
T3结构体分两段:
| 类型 | 长度 |
|---|---|
| 8 | 8 |
| 1+4 | 8 |
现在对字节对齐已经有了一个比较深刻的认识了大,他是由于计算机在高速读取的时候为了保证读取效率而设计的,但是我们在做嵌入式开发钟数据处理和传输数据的时候,经常设计一些自定义的通信协议,如果按照这种设计反而会降低通信效率,而且如果接收方不清楚这些内容可能会引起一些问题,因此也有一定的方法来取消字节对齐或者自行设计对齐的长度。
· 使用伪指令#pragma pack (n),编译器将按照n个字节对齐;
· 使用伪指令#pragma pack (),取消自定义字节对齐方式。
注意:如果#pragma pack (n)中指定的n大于结构体中最大成员的size,则其不起作用,结构体仍然按照size最大的成员进行对界。
另一种方式比较简单,直接在结构体后面加上__attribute__((packed)),这个是直接取消字节对齐的,或者用__attribute__((aligned(n))),这个跟pragma pack (n)效果相同。
可以尝试下面的例子:
1 | #include "stdio.h" |
输出为”8 8 24”,有兴趣可以自己对比前面的内容并且简单计算一下。